
AWS
Do You Really Need a Data Warehouse? Redshift vs. RDS on AWS
A question I wish I had asked a year ago is whether my company really needed a data warehouse like Redshift, or whether we could have gotten by on an RDS instance. If you’re setting up your analytics infrastructure, I recommend you ask yourself the same question. A data warehouse like Redshift, Snowflake, or BigQuery has obvious benefits – size, scalability, and performance on queries that require large scans. But for many startups and early stage companies, I’d consider saving a bit of money by getting by on an RDS instance until you reach its limits.
For the comparable dc2.large and db.t2.large instances, Redshift costs $0.25/hour (or $180/month) and Postgres on RDS costs $0.145/hour (or $104.40/month). RDS is 42% cheaper than Redshift. Smaller instances are available on RDS, allowing you to start at just $13/month for a db.t2.micro instance and scaling up from there, whereas Redshift’s smallest instance is the dc2.large at $180/month.
The key advantage of Redshift that I’ve experienced is the SORT KEY feature. For a table with millions of rows, you can define a SORT KEY column to help query performance improve. For example, if you have a table of all messages sent on your product, and there are 1 million messages per day, you’ll be adding 30 million rows to your Messages table each month. Eventually, on an unoptimized database, query performance will slow dramatically as the database has to scan the entire table to find the messages you are querying for. But with Redshift, the SORT KEY column tells the database to store rows in an organized fashion on blocks of memory. The database stores meta data about what is stored on each block. Then, when you query and specify a range for your SORT KEY column, the query optimizer will know to only scan the relevant blocks of memory, rather than all of them.
Careful schema design on a normal RDS database will take you pretty far with improving query performance. And for smaller datasets, you can be sure that query performance will likely be faster than on Redshift. Redshift is built for intake and storage of large data sets, but less performant for queries. RDS is more of a “jack of all trades” database, but will underperform with massive tables. I’d consider that threshold to be on the order of 100 million to 1 billion rows in a table. When a table reaches that size, it’s likely time to consider moving to Redshift.
The data intake performance of RDS vs. Redshift is likely going to be about the same if you do it right. Both have my coveted COPY command available for loading CSV files directly into the database (rather than running a massive INSERT). COPY, for me and others, is extremely fast for loading lots of data. Redshift might be better if you’re loading <1 million rows / day into a given table, while RDS might be the better option if you’re loading single rows at a time.
To summarize: Unless you have a table of 100M rows or more, you’re probably fine starting out with RDS and then migrating to the more expensive Redshift when you start to hit the limits of RDS’s performance capabilities.
AWS Glue First Impressions
AWS Glue is a managed ETL (Extract, Transform, Load) service for moving data between AWS products such as S3, RDS, and Redshift. I tested it out for moving S3 data into Redshift, and transforming JSON data to CSV format in S3.
How It Works
Although the split concepts of Crawlers, Databases, Tables, Jobs, and Triggers is confusing at first, the product is fairly easy to use after enduring the initial learning curve. Here’s how I would break it down.
Crawlers look at your data source and try to understand the schema of the data it contains. It stores that schema as a…
Table which is part of a Database. A Table is essentially a virtual object definition, created by a Crawler. It can be the schema of CSV’s in S3 (and many other data formats in S3), or an actual database table from Redshift, RDS, or any database that is accessible via JDBC. Once you have at least one Table defined, you can move the data using a Job.
A Job is a task that copies data from one place to another. You can move S3 data to Redshift, copy a Redshift table to S3, copy an RDS table to Redshift…the sky’s the limit.
A Trigger is a configuration for when to run a Job or set of Jobs. This can be on a schedule, such as daily, or fired on Job Events, such as when a Job succeeds or fails.
How It Performed In My Limited Testing
I set up several Crawlers, Tables, and Jobs to test out Glue. One was simply taking a set of JSON files in S3 (approximately 90,000 files of under 1MB each) and flattening them to CSV files, storing the new files in S3 as well. All told, this is about 7GB of total data to be transformed. (more…)
Upgrade Your Amazon Redshift Cluster from DC1 to DC2 Nodes
Our Redshift data warehouse is still relatively small – about 40GB of disk space used, which for us is about 1 billion rows – so we only need a single node cluster. When I created the cluster in September 2017, the DC1 generation was the only type of node available.
While perusing the Stitch blog yesterday, I saw an article about upgrading from DC1 to the new DC2 node type. These are the same price as DC1 instances of the same size, but I/O is significantly higher, and for dc2.8xlarge, ECU is slightly lower (104 units down to 99 units on DC2). Stitch is an ETL or data pipeline tool, moving cloud applications’ data into your data warehouse of choice.
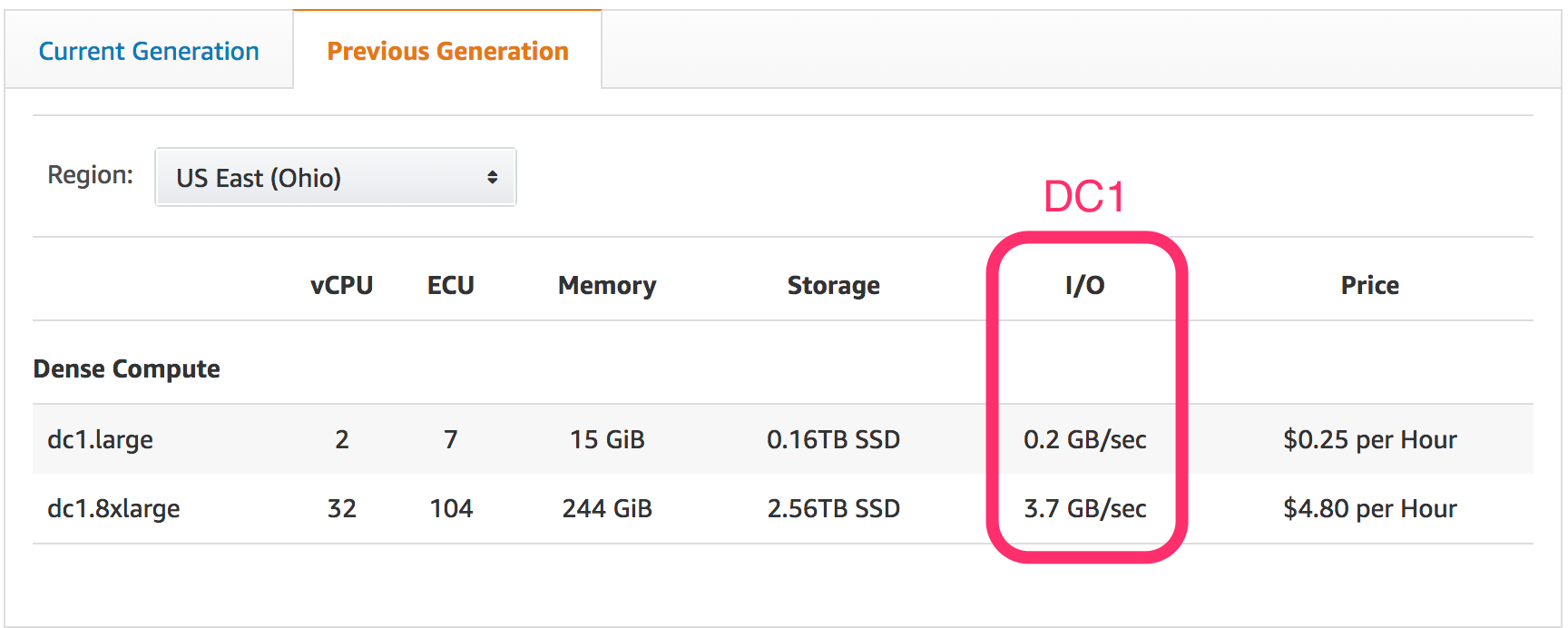
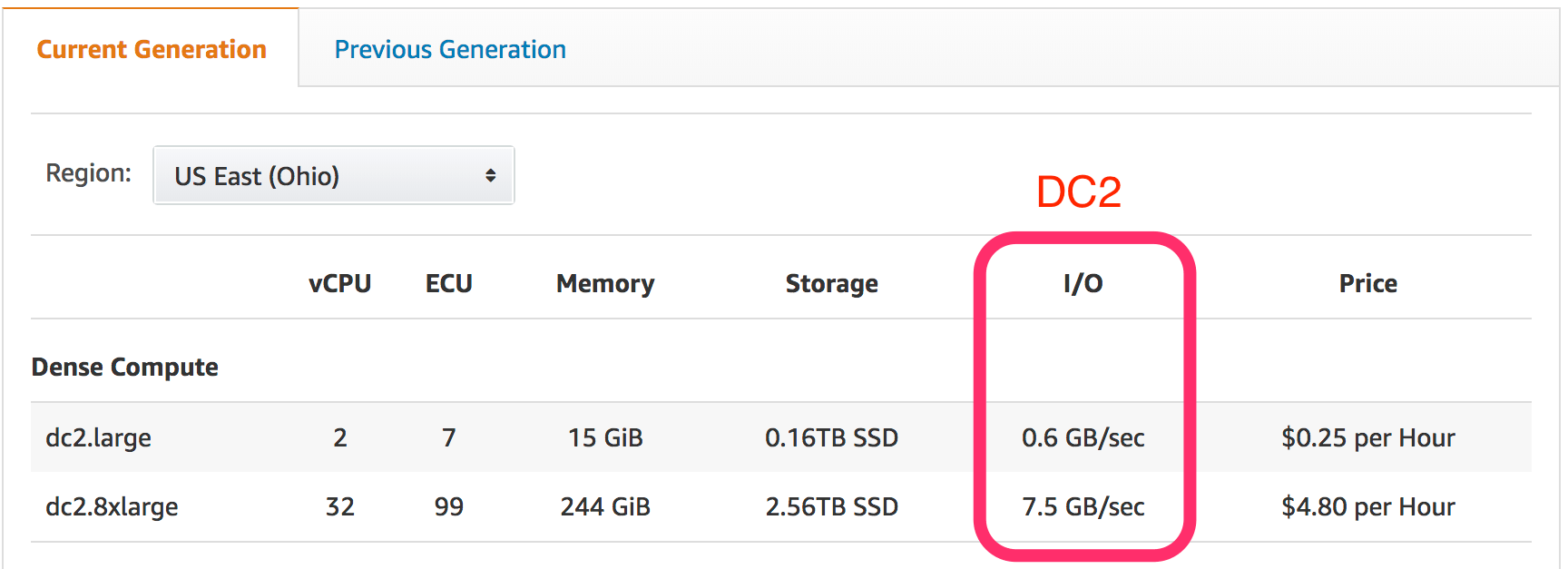
Upgrading to DC2 is simple. In the AWS Console, when on the dashboard for your Redshift cluster, click the “Cluster” dropdown and select “Resize.” (more…)