

I'm the Analytics Therapist at Redox, a quickly growing technology platform that enables organizations to send healthcare data back and forth. Here, I write about our journey to become a data-driven organization, and the technical challenges I've faced along the way. All views and opinions are my own and do not represent those of my employer.
AWS Glue First Impressions
AWS Glue is a managed ETL (Extract, Transform, Load) service for moving data between AWS products such as S3, RDS, and Redshift. I tested it out for moving S3 data into Redshift, and transforming JSON data to CSV format in S3.
How It Works
Although the split concepts of Crawlers, Databases, Tables, Jobs, and Triggers is confusing at first, the product is fairly easy to use after enduring the initial learning curve. Here’s how I would break it down.
Crawlers look at your data source and try to understand the schema of the data it contains. It stores that schema as a…
Table which is part of a Database. A Table is essentially a virtual object definition, created by a Crawler. It can be the schema of CSV’s in S3 (and many other data formats in S3), or an actual database table from Redshift, RDS, or any database that is accessible via JDBC. Once you have at least one Table defined, you can move the data using a Job.
A Job is a task that copies data from one place to another. You can move S3 data to Redshift, copy a Redshift table to S3, copy an RDS table to Redshift…the sky’s the limit.
A Trigger is a configuration for when to run a Job or set of Jobs. This can be on a schedule, such as daily, or fired on Job Events, such as when a Job succeeds or fails.
How It Performed In My Limited Testing
I set up several Crawlers, Tables, and Jobs to test out Glue. One was simply taking a set of JSON files in S3 (approximately 90,000 files of under 1MB each) and flattening them to CSV files, storing the new files in S3 as well. All told, this is about 7GB of total data to be transformed. (more…)
Upgrade Your Amazon Redshift Cluster from DC1 to DC2 Nodes
Our Redshift data warehouse is still relatively small – about 40GB of disk space used, which for us is about 1 billion rows – so we only need a single node cluster. When I created the cluster in September 2017, the DC1 generation was the only type of node available.
While perusing the Stitch blog yesterday, I saw an article about upgrading from DC1 to the new DC2 node type. These are the same price as DC1 instances of the same size, but I/O is significantly higher, and for dc2.8xlarge, ECU is slightly lower (104 units down to 99 units on DC2). Stitch is an ETL or data pipeline tool, moving cloud applications’ data into your data warehouse of choice.
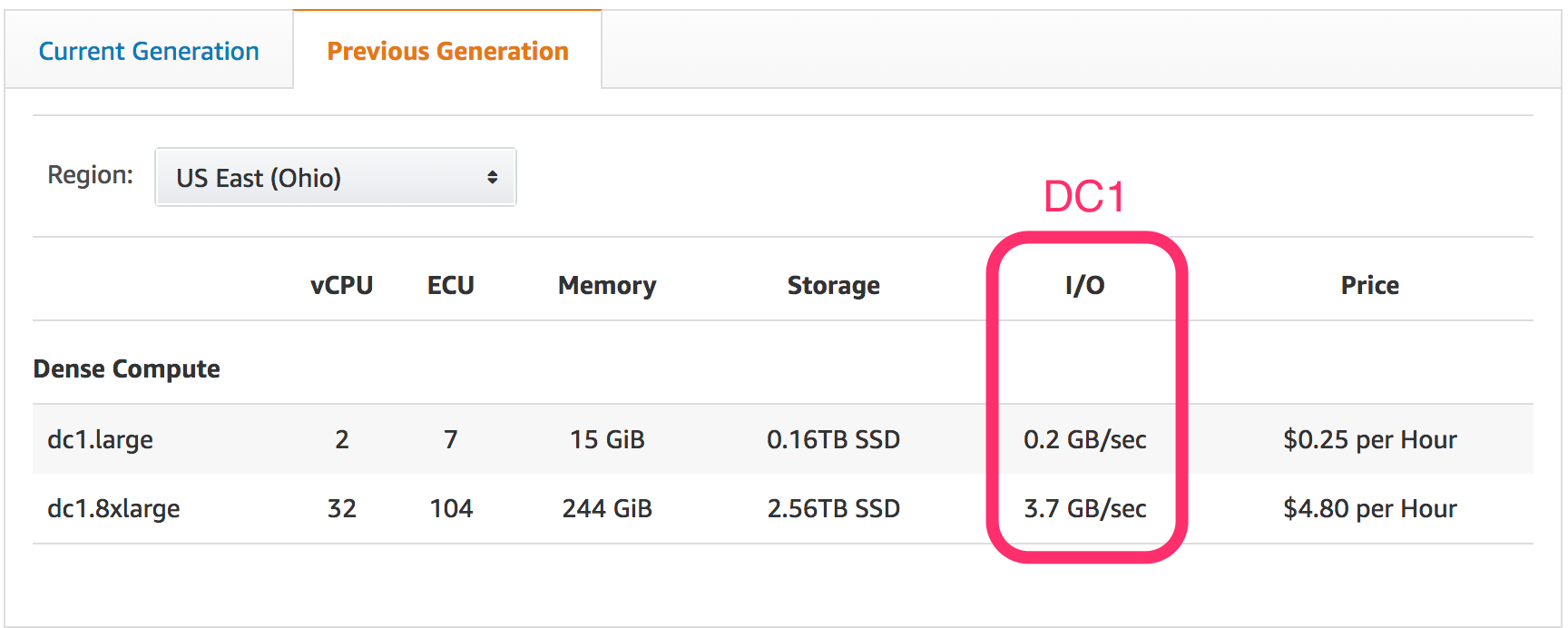
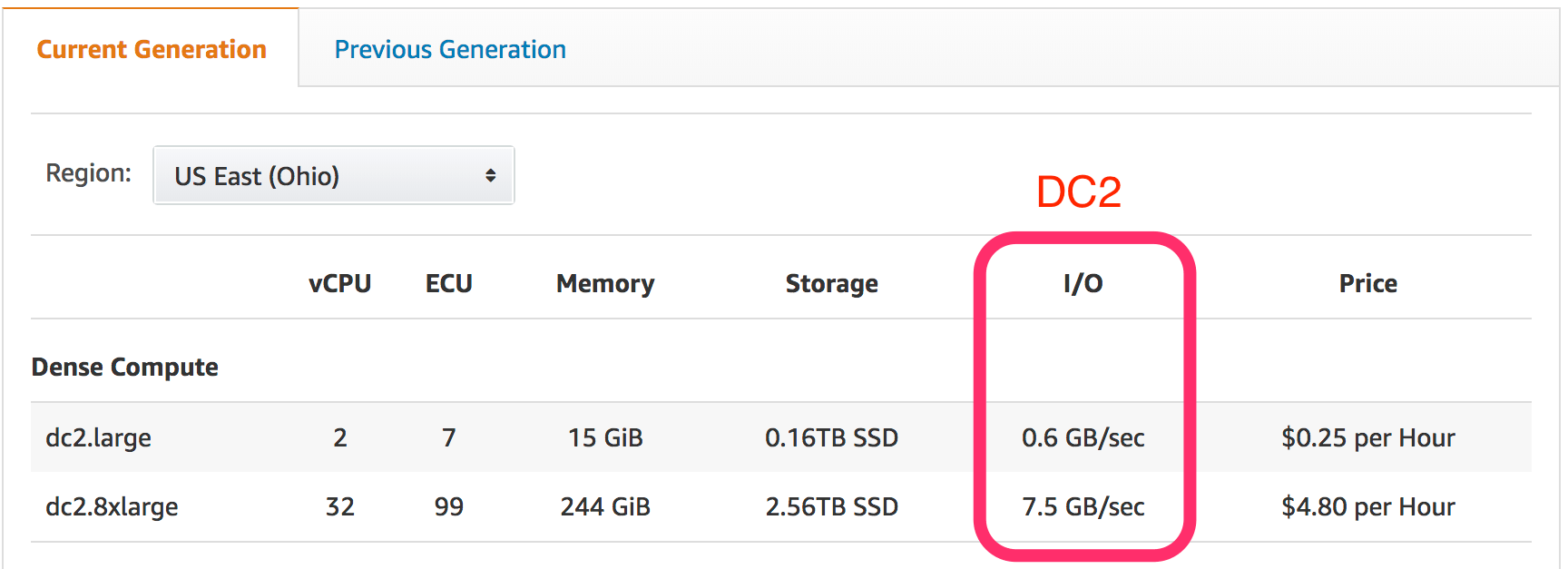
Upgrading to DC2 is simple. In the AWS Console, when on the dashboard for your Redshift cluster, click the “Cluster” dropdown and select “Resize.” (more…)